Understanding Vectors and Embeddings in Machine Learning
A plain-language explanation of how vectors and embeddings power modern ML recommendation systems.
Understanding Vectors and Embeddings in Machine Learning
At NeuronSearchLab, we often talk about vectors and embeddings when describing how our recommendation engine works. These terms are central to the magic behind personalized experiences, yet they can sound a little intimidating if you're not deep into machine learning.
In this post, we’ll break them down simply—so whether you’re a developer, product manager, or business stakeholder, you can better understand how modern recommendation systems like ours use them to deliver relevance at scale.
What Are Vectors in Machine Learning?
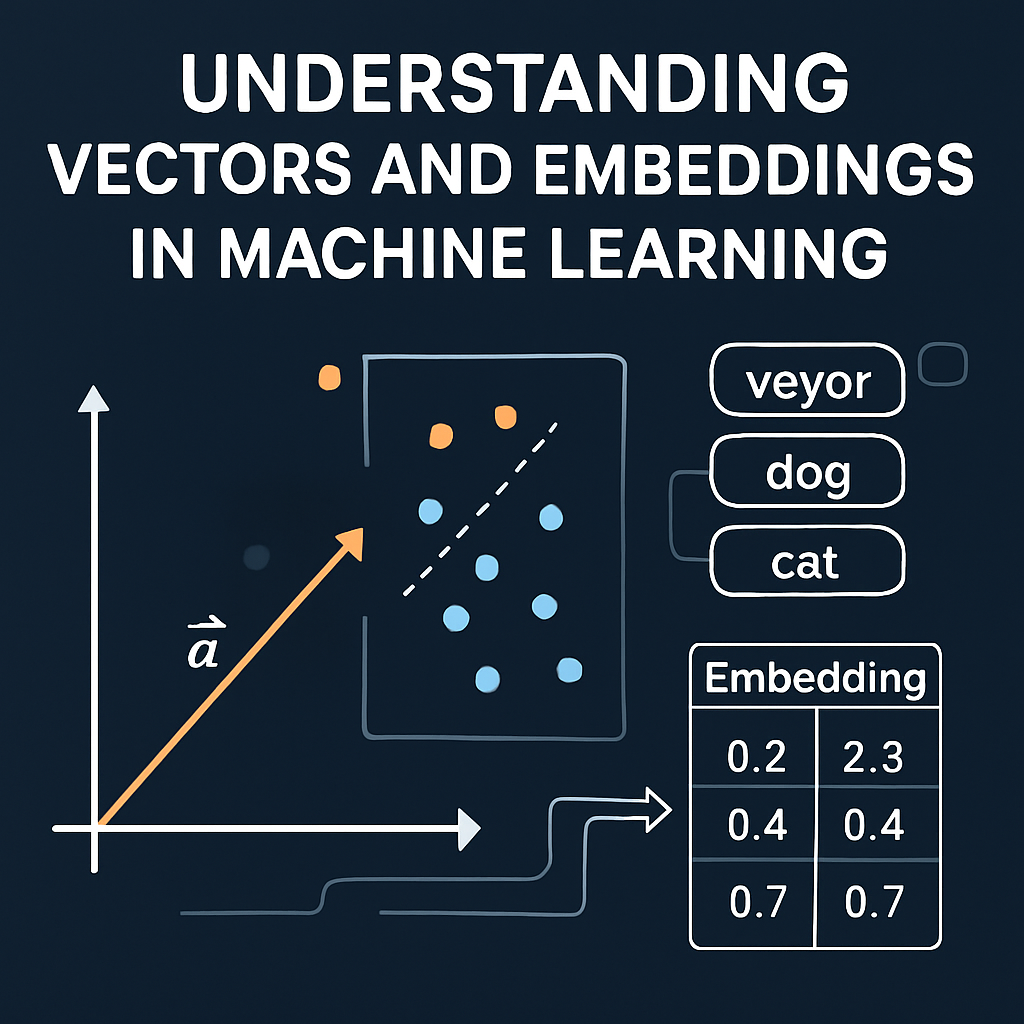
Think of a vector as a list of numbers. Each number represents a feature or attribute of something—like a product, a user, a song, or a movie. These lists (or vectors) live in a mathematical space that allows us to compare things by measuring the distance or angle between them.
For example:
User A: [0.8, 0.1, 0.5] Product B: [0.7, 0.2, 0.6]
These two vectors are close to each other, meaning User A is likely to be interested in Product B.
In simple terms: closer vectors = more similarity.
So, What Are Embeddings?
Embeddings are vectors learned by a machine learning model to represent complex data—like text, images, or user behavior—in a way that captures meaning or context.
Let’s say you’re looking at books. A traditional database might categorize books using genres. But embeddings go deeper. A neural network might learn that "sci-fi thrillers" and "cyberpunk novels" are semantically close—even if they have different labels—based on how users interact with them.
Embeddings let us answer questions like:
- “Which items are similar to this one?”
- “What kind of content does this user engage with?”
- “What products are likely to be relevant in this context?”
Why Does NeuronSearchLab Use Them?
At NeuronSearchLab, we use embeddings to represent users, items, and even context in a shared space. This lets us:
- Personalize content for each user in real-time
- Group and rank content based on nuanced similarities
- React to new data quickly, even with previously unseen items
By comparing these embeddings using cosine similarity, we can deliver recommendations that feel intuitive—like a friend who just gets your taste.
The Neural Network Bit
Behind the scenes, a neural network is trained on historical interaction data (like clicks, purchases, views). It learns to convert each input—whether that’s a user profile or an item description—into an embedding.
Once trained, the model becomes incredibly efficient at generating embeddings on the fly, allowing us to support fast, intelligent recommendations via our API.
Real-World Examples
- Spotify uses embeddings to map songs and user listening habits into a shared space for playlist generation.
- Amazon uses product and user embeddings to power “You might also like” sections.
- NeuronSearchLab gives you the same superpowers—through a flexible API and an intuitive UI for logic customization.
Wrapping Up
Vectors and embeddings may sound like technical jargon, but at their core, they’re just smart ways to represent and compare things. They unlock the ability to personalize experiences, even at massive scale.
At NeuronSearchLab, we’ve built our platform from the ground up with these principles in mind—so you can offer smarter, faster, and more relevant experiences to your users with minimal setup.
Want to see embeddings in action? Try our recommendation API →
Frequently Asked Questions
What is a vector in machine learning?
⌄
A vector is a list of numerical values that represent features of an object—like a product, user, or piece of content—in a format that a machine learning model can understand and compare.
What are embeddings?
⌄
Embeddings are vectors that have been learned by a machine learning model to represent complex data in a way that captures deeper meaning, context, or relationships between items.
How do embeddings help with recommendations?
⌄
Embeddings let systems compare users and items based on their proximity in a shared space. This enables personalized recommendations by identifying similar patterns or preferences.
Why does NeuronSearchLab use embeddings?
⌄
NeuronSearchLab uses embeddings to represent users, items, and context in a unified space—allowing for real-time, accurate, and context-aware recommendations via API.
Are embeddings better than traditional filtering?
⌄
Yes. While traditional filters rely on explicit attributes, embeddings uncover deeper patterns based on behavior, leading to more personalized and relevant results.